A Close Reading of Self-Attention
2025-07-12
Framing self-attention in terms of convex combinations and similarity matrices, aiming to precisely ground common intuitive explanations.
This article assumes comfort with linear algebra. It’s designed for those who have seen the self-attention formula but haven’t yet found the time to really understand it (i.e., me).
Self-attention is a mechanism in deep learning that allows positions in sequences to aggregate information from other positions of their ‘choosing’, depending on the specific input. We’ll make this intuition precise.
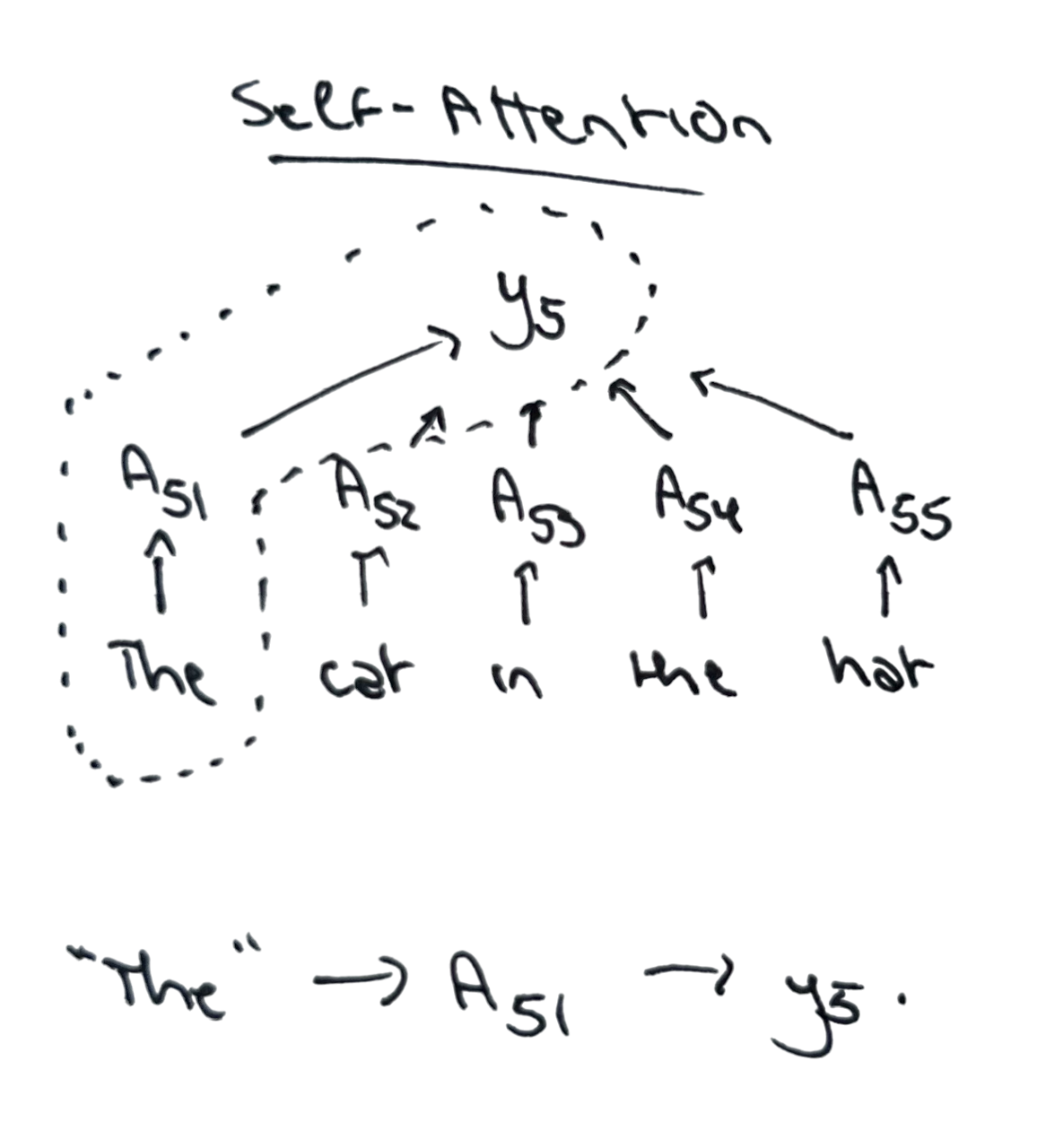
For starters, self-attention is a sequence-to-sequence map. Each element of the output sequence is a weighted average of feature vectors, where the weights and feature vectors are determined from the input sequence.
Mathematically: Self-attention maps an -element sequence of -vectors, , to another -element sequence of -vectors, . Its elements are given by for a weight matrix whose rows sum to one: . The th output vector is the weighted average of feature vectors .
Feature vectors,
The feature vectors are a linear projection of the input. For an input sequence , the feature matrix is for some low-dimensional projection matrix . Think of as a batched projection of , so each sequence element is passed through the same projection.

Attention matrix,
The ‘weight’ matrix is a normalized similarity matrix, where each entry represents a measure of “alignment” between and . Alignment is measured through the kernel matrix,for some learnable matrix . Each element represents the dot product (in the geometry defined by ) between input vectors and . The matrix may be asymmetric, soin general.
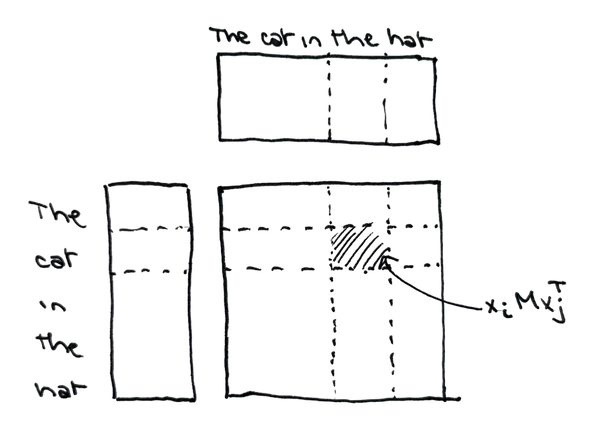
The attention matrix is constructed by passing this kernel matrix through an element-wise nonnegative function , then normalizing each row to have unit sum. Specifically, In practice, is often chosen to be .1 With this choice, can be concisely expressed as the result of a softmax operation applied rowwise:
Convex combinations,
With and defined, we can pull together a precise understanding of self-attention.
Self-attention maps one sequence to another of the same length. Each element in the output sequence is a convex combination of linear features of the input sequence . Each combination weight is determined based on the kernel similarity between and , normalized by its similarities to all other sequence elements.2
Parameterizing
In practice, we don’t learn the bilinear form matrix directly. Instead, we constrain its rank (and hopefully make it easier to learn) by parameterizing as a product of lower-dimensional factors.
We pre-specify a maximum rank , and parameterize in terms of learnable matrices , as follows: The product is scaled by to limit the magnitude of the entries in practice. The goal is to avoid pushing the softmax inputs into regions where the nonlinearity has very small gradients.
The usual notation
Translating from our expression to the form generally seen in papers, is quite simple.
To do so, we define the usual matrices by “pulling” the factors and onto each term in the kernel matrix computation. Specifically, define as Like with the projection matrix above, this operation is best understood as a “batched projection.” The two notations are then trivially equivalent, withAll together:
So what?
Abstractly, this article frames self-attention as the composition In words, self-attention computes an output sequence where each element is a convex combination of feature vectors . The contribution of vector to the output (the magnitude of its combination weight, ) is determined by a normalized kernel similarity between input elements and .
This framing makes apparent some otherwise hand-wavy observations.
Observation 1: Self-attention reduces the ‘distance’ between tokens and
Self-attention is a powerful mechanism because it calculates each output element by directly pulling information from other tokens . Compare this to the dependency between tokens in a recurrent neural network. Define the basic RNN as Each output computed, , is the result of recursive applications of and along the input sequence. The information about early tokens is bottlenecked through the single “hidden state” representation .
In theory, should be able to represent all the relevant information from the previous sequence tokens. But in practice, RNNs don’t learn to compress this information well.3
 Self-attention sidesteps this compression problem. It removes the hidden state bottleneck and directly mixes features from other tokens.
Self-attention sidesteps this compression problem. It removes the hidden state bottleneck and directly mixes features from other tokens.
 In doing so, self-attention also parallelizes the sequence-to-sequence computation.
In doing so, self-attention also parallelizes the sequence-to-sequence computation.
RNNs are inherently sequential, since their output at time depends on the previous hidden state . But with self-attention, each output term and can be computed completely in parallel.
This parallelization, however, does come at a cost.
Observation 2: Self-attention has no “interaction terms”
Because self-attention parallelizes the similarity computation for output across all input elements at once, it’s quite restricted in the way it can combine information from input tokens.
Specifically, self-attention can only ‘combine’ information from tokens into through the linear mixing Even the linear mixing weights and depend largely only on the individual similarities and . This turns out to limit the kinds of computations that (a single layer of) self-attention can perform.4
Various generalizations of self-attention aiming to address this limitation by incorporating interaction terms have been proposed.
The basic concept of “higher-order attention” is simple, and fits nicely into the framework we’ve discussed. For concreteness, let’s consider third-order attention.5
Third-Order Attention
There are two key changes. Rather than mixing individual features associated with individual tokens , we mix pair features associated with token pairs . Rather than defining the mixing weights for output using the similarity between and all other tokens , we mix the pair features based on the similarity between and all pairs of tokens .
The final form of third-order attention is semantically equivalent to standard attention. It composes an output sequence composed by linearly mixing interaction features from the input: Recent research has demonstrated practical performance improvements from incorporating higher-order attention layers (Roy et al, 2025).
But unfortunately, there are no free lunches. Higher-order attention is significantly more expensive. Whereas standard self-attention is , third-order attention is , since we now need to compute an attention tensor rather than an attention matrix.
Conclusion
We’ve now thoroughly examined each component of self-attention. The self-attention mechanism is a sequence-to-sequence transformation that computes each output as a weighted average of features, where the weights are based on normalized similarities between input sequence elements. This framing precisely undergirds the intuition that self-attention allows positions to “look at” and “choose” information from other positions.
-
Some interesting papers exploring other nonlinearities: 1, 2, 3. Maybe another blog post to come on this. ↩
-
In practice, we restrict the th output to only pull from the first tokens. This is called causal masking, and is another main reason why transformers are so good at autoregressive generation. ↩
-
There are mathematical arguments for the difficulty of learning these “long-range dependencies,” as well. The rough idea is that the contribution of an input token to a loss at output token decays to zero for . See (Bengio et al, 1994) and (Hochreiter and Schmidhuber, 1997) for more. ↩
-
For example: (Sanford et al, 2023) introduce a task, , that is very difficult for standard attention but trivially solvable for a “higher-order” attention taking into account pairwise interactions. For a single self-attention layer, solving requires an embedding dimension or number of heads that is polynomial in the input sequence length, . By contrast, a “third-order” self-attention layer can solve for any sequence length with constant embedding dimension. ↩
-
The exposition here is roughly based on (Clift et al, 2019) and its recent computationally-efficient reformulation in (Roy et al, 2025). These papers refer to third-order attention as “2-simplicial.” ↩