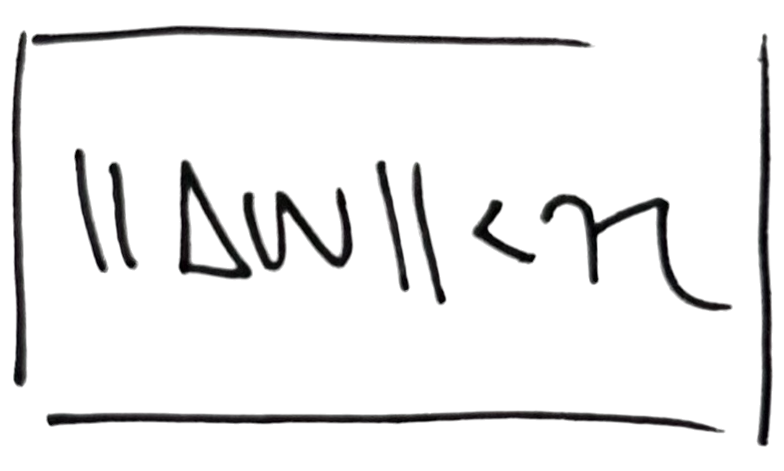
Using basic linear algebra to prove that "orthogonalizing" the gradient gives the optimal loss improvement under a norm constraint.
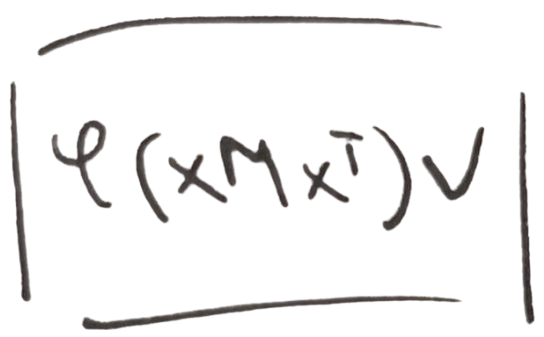
A Close Reading of Self-Attention
2025-07-12
Framing self-attention in terms of convex combinations and similarity matrices, aiming to precisely ground common intuitive explanations.